昆仑万维发布全新大模型奖励模型Skywoyl8cc永利官网rk-Reward登顶RewardBench

这意味着■◆★★,想要在RewardBench基准测试中脱颖而出■◆★,奖励模型不仅需在对话◆■★■■、安全性和推理所有领域上表现出色,还必须在具有挑战性的对抗性案例中展现稳健的应对能力,证明其具备全面的理解能力并能准确识别细微偏好差异。
科技浪潮势不可挡!半导体+AI+消费电子获持续看好!15只滞涨绩优股获资金埋伏
奖励模型(Reward Model)是强化学习(Reinforcement Learning)中的核心概念和关键组成■◆,它用于评估智能体在不同状态下的表现,并为智能体提供奖励信号以指导其学习过程■■■■,让智能体能够学习到在特定环境下如何做出最优选择。奖励模型在大语言模型(Large Language Model★◆■■★◆,LLM)的训练中尤为重要★◆■■★,可以帮助模型更好地理解和生成符合人类偏好的内容。
最后还进行了全面的人工验证,以剔除数据中客观不正确以及奖励差距较小的样本。
首单增持回购再贷款有望落地深圳 知情人士★★◆★■:招商局旗下已有统一部署■◆◆■★◆,最早明后天发布具体消息
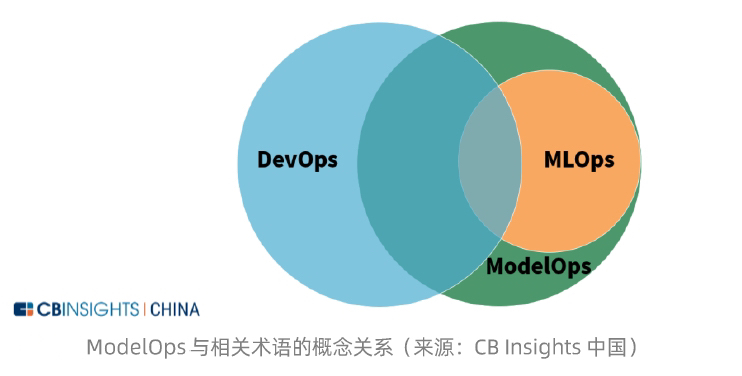
昆仑万维发布的两款全新奖励模型在权威奖励模型评估基准 RewardBench 上表现卓越,分别位列第一和第三位(来源★◆◆■◆◆:RewardBench排行榜)
Skywork-Reward 通过从公开数据中精心挑选小而精的偏序数据集■■★★◆,并使用相对较小的基座模型,来开发最先进的奖励模型。与现有奖励模型不同,Skywork-Reward 的偏序数据仅来自于网络公开数据,采用特定的筛选策略,以获得针对特定能力和知识领域的高质量的偏好数据集。
宁德时代■■:2024年第三季度净利润为131◆■★◆★.36亿元 同比增长25★◆■.97%
这些偏好数据包括由人类标注和合成生成的(问题◆■、被选回答★★、被拒回答),涵盖了广泛的主题,例如来自 WildGuard 的安全性和来自 Magpie 的数学与代码。数据源包括:HelpSteer2(7K)、OffsetBias(8K)、WildGuard(对抗性)(9K),以及 Magpie DPO 系列:Ultra、Pro(Llama-3.1)◆■、Pro、Air(350K)。
此前,最先进的奖励模型是由 NVIDIA 开发的 Nemotron-4-340B-Reward,该模型基于 HelpSteer2 偏好数据集上进行训练yl8cc永利官网,该数据集包括大约 10,000 个人工标注的样本。然而,由于其模型规模庞大,使用成本较高★◆★★■。
金融监管总局副局长周亮★◆◆:与各方一道致力于实现◆■“一带一路”共商共建共享目标
对于 WildGuard◆★◆◆■,并未包括所有的偏好数据,而是首先在另外三个数据源上训练一个27B奖励模型(RM)◆★★◆。然后(1)使用该 RM 对 WildGuard 中所有样本的被选回答和被拒回答进行评分,(2)仅选择那些被选回答的 RM 得分高于被拒回答的样本。团队观察到,这种方法在提升安全性的同时,基本保留了对话、复杂对话和推理领域的性能◆★★◆。
在测试过程中,昆仑万维奖励模型在对话、安全性等领域表现出色,例如在对话■◆、安全、代码推理★★◆★■◆、数据推理等方向的困难样本中■★■,只有 Skywork-Reward-Gemma-2-27B 模型给出了正确的预测(对比模型包括:ArmoRM 和 InternLM2-20B-Reward)★■★。
RewardBench 是专用于评估大语言模型中奖励模型有效性而设计的基准测试榜单。它通过多项任务对奖励模型的表现进行综合评估,涵盖了对话★◆◆★、推理和安全性等领域。RewardBench 的基准测试数据集由提示词、被选响应和被拒绝响应组成的三元组构成,旨在测试奖励模型是否能在给定提示词的情况下★★★★■◆,将被选响应排在被拒绝响应之前◆◆。
为了进一步优化数据集,昆仑万维团队利用数据集的统计信息来进行筛选◆■■★,在不牺牲整体性能的情况下◆★,实现RewardBench各领域之间的性能平衡提升:
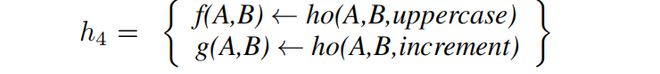 第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序
第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序
 基于特征优化和支持向量机的航空发动机气路故障诊断
基于特征优化和支持向量机的航空发动机气路故障诊断