
第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序合成领域发现抽象map、filter和fold并在国际象棋领域使用它们
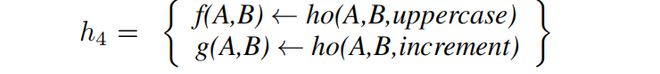
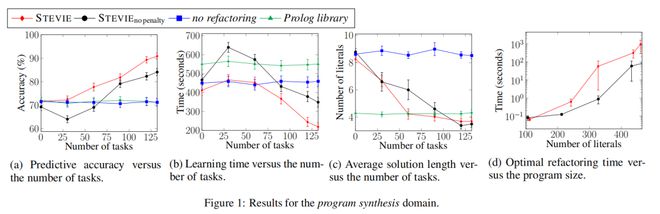
方法。我们测量HOPPER的预测准确性(测试数据上正确预测的比例)和学习时间◆◆。我们为每项任务设定最长学习时间为15分钟■◆,并返回在此时间限制内HOPPER找到的最佳解决方案。我们为STEVIE设定1小时的超时时间◆◆■■◆■,并返回在此时间限制内找到的最佳重构◆■★■。我们重复所有实验5次,并计算平均值和标准误差。图表和表格中的误差线表示标准误差。为了清晰起见,我们在图表中重命名了抽象◆★★。
HOPPER在某些任务上遇到困难,因为STEVIE没有发现有帮助的抽象。例如,任务isPalindrome需要抽象condList,如果输入列表为空则返回真,否则对列表调用谓词。STEVIE没有发现这个抽象,因为它没有压缩输入程序。

假设我们想要重构程序 P = h1 ∪ h2◆■★★◆。在抽象阶段,我们发现 P 的抽象,例如:
我们介绍了一种通过发现高阶抽象来重构逻辑程序的方法。我们在STEVIE中实现了我们的方法,它将这个重构问题表述为一个约束优化问题(COP)。我们在多个领域的实验表明◆■■,高阶重构可以大幅提高归纳逻辑编程(ILP)系统的性能,即提高预测准确性和减少学习时间★■。我们的结果还表明,在一个领域中发现的抽象可以转移到不同领域。例如,我们可以在程序合成领域发现抽象map◆■、filter和fold,并在国际象棋领域使用它们◆★。

在程序合成领域发现抽象map、filter和fold,并在国际象棋领域使用它们。

我们引入了高阶重构问题◆◆,目标是通过发现高阶抽象★■◆★,如map、filter和fold★■■■,来压缩逻辑程序★◆★★■■。我们在STEVIE中实现了我们的方法,它将重构问题表述为约束优化问题。我们在多个领域(包括程序合成和视觉推理)上的实验表明,重构可以提高归纳逻辑编程系统的学习性能,具体来说,提高了27%的预测准确性■◆★■◆,并减少了47%的学习时间。我们还展示了STEVIE能够发现可以转移到多个领域的抽象。
为了回答Q1,我们比较了具有和不具有使用STEVIE发现的抽象能力的ILP系统的性能。我们使用ILP系统HOPPER[Purgal等人,2022]★■■◆,因为它可以学习递归程序,执行谓词发明◆■◆★★,并使用高阶抽象作为BK3。
表1显示了预测准确性。学习时间在附录中。这些结果表明■◆★,转移抽象(i)永远不会降低准确性,并且(ii)可以在5/7的迁移领域提高准确性◆★■◆。配对t检验确认(p 0◆★■■◆.01)表1中所有任务的准确性差异的显著性,除了长度任务◆★■◆◆。例如,STEVIE在程序合成领域发现了抽象filter和map,HOPPER利用这些抽象来完成字符串任务string1,学习一个程序■◆★◆,该程序移除小写字母并将剩余字母小写化★■。HOPPER还重用这些抽象来学习任务chessmapfilter的解决方案。类似地,HOPPER重用抽象until在ASCII艺术领域绘制对角线)。
领域。我们使用包含176个程序合成任务的数据集,并保留25%作为保留任务。这些任务旨在使用各种高阶构造,并需要学习递归程序◆★。例如★◆■■■,数据集包括counteven、filterodd(图2a)和maxlist(图3b)等任务★◆★★。附录包含了更多细节,如示例解决方案。
近期在归纳逻辑编程(ILP)中的工作表明,使用用户提供的高阶抽象,如map■★★、filter和fold★■,可以大幅提高ILP系统的性能[Cropper等人★★■★■◆,2020★★◆; Purgal等人★◆,2022]★■■★。例如,如果将map作为输入★◆,这些方法可以学习到前面提到的高阶字符串转换程序★★★◆■。
重构时间。实验3表明■◆■◆,STEVIE可以在16分钟内最优地重构大约460个文字的程序,但在更大的程序上存在困难。未来的工作应该提高可扩展性◆■★■◆★,例如改进我们的COP编码和使用并行COP求解。
在这个程序中,关系 f 和 g 是用抽象 ho 定义的。正如这个例子所示,抽象可以压缩程序,即 P 的字面量(14个)比 P(20个)少。

发明的关系 ho 定义了一个高阶抽象■■,它对应于 map。符号 X 是一个高阶变量,它量化在谓词符号上★◆■■■◆。
正如我们在实验中所展示的,这种惩罚使我们能够找到能够带来更好学习性能的抽象。
我们假设熟悉逻辑编程[Lloyd, 2012],但已在附录中包含了一个摘要★■★。我们重申关键术语。一阶变量可以绑定到常量符号或其他一阶变量。高阶变量可以绑定到谓词符号或其他高阶变量。一个子句是一组文字■★。如果它至少有一个高阶变量■◆,则该子句是高阶的★◆■◆◆。一个确定子句是一个恰好有一个正文字的子句。我们将术语规则与确定子句同义。一个确定程序是一组具有最小Herbrand模型语义的确定子句。我们将确定程序称为逻辑程序◆◆■★★。如果逻辑程序至少有一个高阶子句,则它是高阶的■◆★◆◆。逻辑程序P的大小(size(P))是P中文字的数量■■。定义是具有相同头部谓词符号(正谓词符号)的一组规则。逻辑程序P的定义集合★■■◆,头部谓词符号为T★◆◆■■,是 δ(P) = ∪p∈T {r ∈ P 规则r的头部谓词符号是p}。
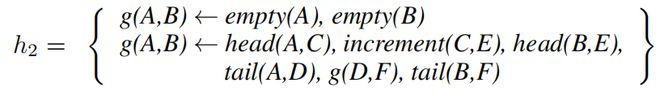
为了理解对高阶变量数量进行惩罚(第4◆◆★.2节中的组件(3))的影响★★,我们的实验旨在回答以下问题:
在压缩阶段,STEVIE搜索一组可以压缩输入程序的抽象和实例化(第3行)◆◆◆。STEVIE将这个搜索问题表述为一个约束优化问题(COP)。给定(i)一组决策变量★◆,(ii)一组约束,以及(iii)一个目标函数,COP求解器找到一个满足所有指定约束并最小化目标函数的决策变量赋值。
为了测试我们的论断,即高阶重构可以提高归纳逻辑编程(ILP)系统的性能,我们的实验旨在回答以下问题:
STEVIE施加两种类型的约束■◆★。首先,对于每个定义d ∈ δ(P)■★■◆■,STEVIE使用一个约束来确保最多为d选择一个实例化:

这个函数还通过用ψ替换抽象中的谓词变量来返回一个实例化(定义2)★■■★。STEVIE剪枝那些在头部谓词符号的重命名下相同的抽象(第11行)。在这种情况下,STEVIE根据现有的等价抽象重新定义实例化(第12行)。例如,考虑以下规则★◆◆:
• 我们引入了 STEVIE,它通过将其表述为 COP 来发现高阶抽象◆■■★■◆,并找到高阶重构问题的最优解。
实验1探索了发现抽象是否能提高单一领域的学习性能。现在我们探索在一个领域中发现的抽象是否能提高不同领域的性能■★。

抽象被看作是人工智能的关键[Saitta和Zucker★■◆■◆, 2013★★■; Russell■★◆★, 2019■■★★◆; Bundy和Li★★◆■■, 2023]。尽管其重要性被广泛讨论,但在机器学习中抽象常常被忽视[Marcus, 2020; Mitchell, 2021]◆★■★◆◆。为了解决这一限制,我们提出了一种方法■■◆◆★■,该方法自动发现高阶抽象以提高机器学习算法的学习性能。
为了克服这个限制◆■★★★◆,我们引入了一种自动发现有用高阶抽象的方法,这些抽象随后可以被ILP系统使用★■◆■★◆。这个想法是通过发现压缩它的高阶抽象来重构逻辑程序。
其次,对于每个抽象a ∈ A(P),STEVIE使用一个约束来确保变量s_a为真当且仅当使用a的一个实例化来重构至少一个定义时■◆◆:
为了说明高阶重构,考虑filterodd和filterpos任务。图2a和2b显示了HOPPER为这些任务学习到的程序。STEVIE通过发现图2c中显示的抽象来压缩这些程序。这个抽象保留了列表中高阶谓词Y成立的元素,并移除了高阶谓词X成立的元素,即这个抽象过滤了一个列表◆★★■■。因此,STEVIE将程序从30个文字(图2a和2b)压缩到19个文字(图2c和2d)■★★◆■★。
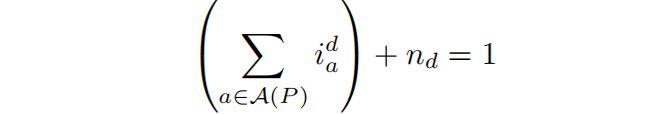
领域。我们使用35个现有的任务◆★,所有这些任务都受益于高阶抽象[Lin等人◆★,2014; Cropper等人◆■◆■,2020; Cretu和Cropper,2022★■★◆◆■; Purgal等人◆◆■■★,2022]。这些任务来自7个领域■◆■◆■:国际象棋、ASCII艺术◆★、字符串转换★◆★■◆、机器人策略、列表操作★★★★、树操作和算术。这些领域的背景知识(BK)差异很大■■■★★,重叠很少。附录中包含了对这些领域的描述。
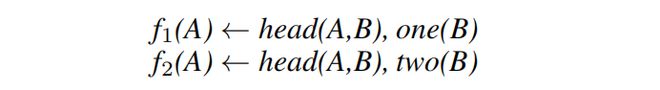
表示变更。Simon[1981]将抽象视为改变问题的表示方式◆■★,使其更容易解决■■■★◆■。命题化[Lavrac和Dzeroski■★■◆★, 1994★★; Paes等人★■◆◆,2006]将一阶问题转换为命题问题★★,以使用高效的命题学习算法澳门永利皇宫官网入口★◆。命题化的劣势是失去了紧凑的表示语言(一阶逻辑)。相比之下◆◆★,我们将一阶问题转换为高阶问题■■★★■■。理论修订[Ad´e等人,1994; Richards和Mooney, 1995; Paes等人,2017]修订程序,使其包含缺失的答案或不包含不正确的答案。理论精细化提高了理论的质量,如其执行或可读性[Sommer★★◆■, 1995; Wrobel, 1996]。相比之下■◆■◆,我们重构理论以提高学习性能。
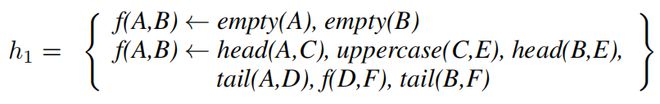
这一结果表明,并非所有抽象都有助于学习,找到好的抽象是很重要的。总体而言,这些结果表明■◆◆◆◆,对高阶变量数量进行惩罚可以提高学习性能(Q2)。
(i)考虑逻辑程序,(ii)保证最优压缩■★,并且(iii)可以跨领域传递知识■★◆★。此外,这些方法只评估压缩率,而我们展示了压缩程序可以提高ILP系统学习性能。
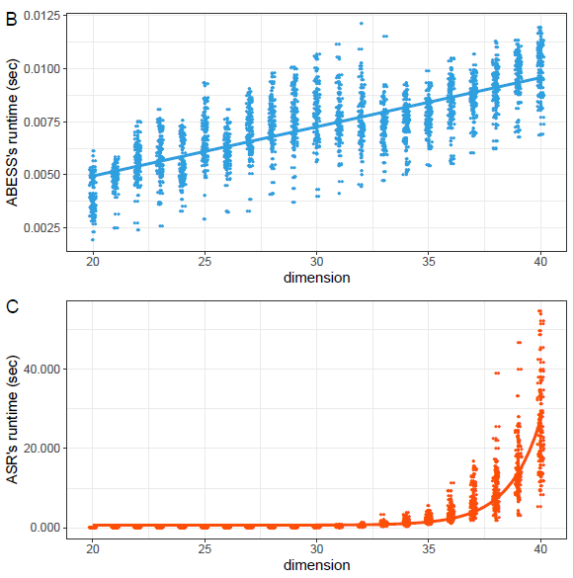
图1d显示了STEVIE在逐渐增大的程序上的运行时间。运行时间随着程序大小(文字数量)的增加而呈指数级增长。随着大小的增加,STEVIE构建了更多的抽象,导致压缩阶段的决策变量更多。请注意,运行时间是STEVIE找到最优重构并证明最优性所需的时间。正如Dumanˇci´c★◆、Guns和Cropper[2021]所示,对于重构问题◆★■★◆★,求解器可以快速找到一个几乎最优的解决方案,但需要一段时间才能找到最优的解决方案★■◆■。总体而言,这些结果表明■★◆★◆,STEVIE在证明最优性方面的可扩展性是有限的(Q3)★■◆◆。
• 我们在多个领域评估了我们的方法■◆,包括程序合成◆◆★、视觉推理和机器人策略学习。我们的实验结果表明,重构可以提高 ILP 系统的性能,具体来说■★■,提高了预测准确性 27%,减少了学习时间 47%。我们还展示了发现的抽象可以在不同领域之间重用。
证明在附录中。为了展示这个结果★■◆■★◆,我们展示了(i)STEVIE生成了所有抽象和实例化(定义1和2)■■◆,(ii)编码的任何解决方案都是高阶重构问题的解决方案(定义4)◆★◆■◆★,以及(iii)求解器找到了关于我们目标函数的最优解决方案(定义5)。
上述场景展示了如何在一个领域中发现高阶抽象,通过允许归纳逻辑编程(ILP)系统学习更小的程序★◆◆,从而帮助该系统在该领域表现得更好。在本文中,我们展示了在一个领域(如程序合成)中发现的抽象,可以被 ILP 系统在不同领域(如国际象棋)中重用。尽管有关迁移学习[Torrey和Shavlik, 2009]和跨领域迁移学习[Kumaraswamy等人,2015]的研究很多■◆★◆★■,据我们所知■◆★■◆★,我们是第一个展示自动发现跨领域泛化的抽象。

在抽象阶段(第2行),STEVIE构建抽象和实例化。为了构建逻辑程序P的抽象,对于每个定义d ∈ δ(P)和d中规则体中最多k个谓词符号的子集ψ,STEVIE调用函数create abs inst(d, ψ)(第10行)。值k是用户参数■■★★◆。这个函数遵循定义1■★★◆,用新的高阶变量xi替换ψ中的每个pi★■◆★,将每个xi添加到谓词符号h的字面量参数中★★■★◆■,其中h是定义d的头部谓词符号■★■◆◆,并将h的每个出现替换为发明的谓词符号h。例如,如果d是示例1中的规则,ψ={head■★◆★◆, one},该函数用X替换head,用Y替换one,以构建示例1中的抽象ho3。STEVIE从不抽象递归谓词符号(第9行),因为这会改变语义。
HOPPER还因为类型不一致而在某些任务上遇到困难。例如◆★★■◆★,任务droplast涉及学习一个程序◆◆,该程序给定一个列表的列表,从每个列表中删除最后一个元素。STEVIE发现了抽象map。然而,这个抽象适用于类型为列表的参数◆◆◆■,而droplast接受的参数是列表的列表。
这个程序使用了高阶抽象map来避免需要学习如何递归地遍历列表。正如这个场景所示,使用抽象可以使我们学习更小的程序,这些程序通常比更大的程序更容易学习[Cropper等人,2020]。
设置■★★■★■。HOPPER使用类型来限制假设空间(所有程序的集合)■★★。我们采用自下而上的程序来从一阶BK的类型推断STEVIE发现的抽象的类型■■◆★■。我们设置HOPPER在程序中最多使用三个抽象◆◆■。我们允许HOPPER使用三个线程。我们使用SWI-Prolog来执行STEVIE和HOPPER学习的程序★■◆★◆■。我们允许STEVIE发现最多包含三个高阶变量的抽象。
这个程序递归地将每个元素转换为大写◆★★。虽然正确,但这个程序很冗长★★◆◆。或者■★★◆◆★,我们可以学习★◆★:
方法■■。我们的方法有三个步骤。在第一步中◆★,我们使用HOPPER独立学习n个任务的解决方案■■。在第二步中★■◆,我们使用STEVIE重构第一步中学到的程序。在第三步中,我们将STEVIE在第二步中发现的抽象添加到HOPPER的BK中。然后我们使用HOPPER处理保留任务。我们改变第一步中任务的数量n,并测量第三步中HOPPER的性能■■。基线(不重构)是我们在第二步中不使用STEVIE时的情况,即基线是没有STEVIE发现的抽象的HOPPER。作为第二个基线,我们使用了SWI-Prolog库apply4中的七个标准高阶抽象(maplist★◆、foldl◆★■★■■、scanl、convlist、partition、include和exclude)。附录包括这些抽象的描述★■■。
图1a显示,我们的方法(STEVIE)可以将预测准确性提高27%,与基线b显示◆★◆■,我们的方法可以将学习时间减少47%,与基线相比。卡方检验和曼-惠特尼U秩检验确认(p 0.01)准确性和学习时间差异的显著性。

STEVIE使用三种类型的决策变量。首先,对于每个定义d ∈ δ(P)和抽象a ∈ A(P)◆■★★■,我们使用一个布尔变量i_d_a来指示是否选择了定义d的一个实例化。我们稍后使用这些变量来确保一个定义最多只使用一个实例化定义。其次,对于每个定义d ∈ δ(P),我们使用一个布尔变量n_d来指示没有为d选择任何实例化。这些变量允许STEVIE在总体上增加重构程序的复杂性时不引入抽象和实例化。第三■◆◆★◆■,对于每个抽象a ∈ A(P),我们使用一个布尔变量s_a来指示至少选择了a的一个实例化。STEVIE使用这些变量来确定重构程序的大小★◆■■。
作为第二个例子,考虑multlist(图3a)和maxlist(图3b)任务◆■◆★。STEVIE通过发现抽象fold(图3c)来压缩这些程序■◆★◆。这个抽象递归地使用高阶谓词X和由高阶谓词Y给出的默认值结合列表中的元素■◆■。因此★■■★◆■,STEVIE将程序从16个文字(图3a和3b)压缩到12个(图3c和3d)■◆★★。此外◆◆◆■■■,HOPPER重用fold抽象来学习更复杂任务的程序■★◆◆◆。例如◆■■★★★,没有抽象,HOPPER学习sumlistplus3程序需要10个文字(图3e),而有了fold抽象,它只学习了6个文字的解决方案(图3f)。
图1a和1b显示,对高阶变量数量进行惩罚可以将预测准确性提高8%,并将学习时间减少37%。卡方检验和曼-惠特尼U秩检验确认(p 0.01)准确性和学习时间差异的显著性澳门永利皇宫官网入口■◆◆★。这一结果表明,我们目标函数的组件(3)可以帮助提高性能。没有惩罚的情况下,STEVIE会找到许多高阶变量的抽象★◆■。这些抽象帮助较小,因为HOPPER必须搜索所有可能实例化的空间,当有更多的高阶变量时,这个空间会更大。
我们的重构方法分为两个阶段★★■★:抽象和压缩。在抽象阶段,给定一个一阶程序,我们发现高阶抽象★■◆■★★。在压缩阶段◆■★■,我们搜索一组可以压缩一阶程序的抽象子集★◆◆◆★■。
这个程序接收一个自然数列表◆■■■★,并将每个元素加一◆■◆★,例如 [3,4,5] 转换为 [4★◆★★■,5,6]★◆◆■。
图1c显示◆★◆■,重构通常将HOPPER学习到的程序大小从8个文字减少到4个文字★◆★。正如最近的工作所示[Cropper等人,2020◆■■; Purgal等人,2022],学习更小的程序可以提高学习性能,因为系统搜索的是更小的假设空间。
算法1展示了我们的STEVIE算法,它分为两个阶段:抽象和压缩★■■■■。在抽象阶段■◆★,给定一个一阶逻辑程序★★,STEVIE构建抽象和实例化。在压缩阶段,STEVIE搜索一组可以压缩输入程序的抽象和实例化■★■◆。STEVIE将这个搜索问题表述为一个约束优化问题(COP)。我们依次描述这两个阶段■◆★◆★。附录中包含了一个重构的例子。


STEVIE可以发现许多抽象,如map、count、iterate、until、member和all。附录包含了STEVIE发现的所有抽象。HOPPER可以结合这些抽象来学习复杂任务的简洁程序。例如,对于任务sumunicodes■◆★★,HOPPER学习了一个紧凑的解决方案(1条规则和3个文字)◆★,它使用了抽象map和fold(图4)。没有抽象■★◆★,HOPPER需要学习至少5条规则和21个文字的程序。
方法。我们的实验方法与实验1类似,但步骤1和3中的领域不同■■★■。在第一步中■■★★◆,我们使用HOPPER处理程序合成领域的任务■◆■◆★。在第二步中★◆■◆★★,我们使用STEVIE从第一步中学到的程序中发现抽象。在第三步中,我们使用HOPPER处理迁移领域的任务。我们从合成领域的BK类型推断STEVIE发现的抽象的类型■◆■■★。我们使用硬编码的类型映射将抽象的类型映射到迁移领域。我们移除使用在目标领域中不存在的关系的抽象★◆★■,以确保它们可以被执行。基线是我们在第二步中不应用STEVIE的情况■◆■■,即不进行重构。
目标函数■◆★。实验2表明◆■,仅压缩并不是识别最有助于提高学习性能的抽象的最佳指标■◆◆。未来的工作应该研究替代的目标函数。
(1) 未抽象定义的大小,(2) 选定的抽象和实例化的大小,以及 (3) 对高阶变量数量的惩罚。我们依次描述这些。
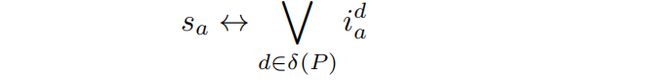
在压缩阶段■◆◆◆■,我们搜索一组可以压缩输入程序的抽象子集。我们将这个问题表述为一个约束优化问题(COP)[Rossi等人,2006]◆◆。我们输出一个带有抽象的重构程序,例如 P = h3 ∪ h4,其中 h4 是★★★◆■◆:
抽象的思想是用谓词变量替换规则体中的谓词符号◆★◆,并将这些变量添加到规则的头部。我们定义一个抽象◆■■■◆:

压缩◆■★★。Chaitin[2006]强调在抽象中压缩。理论压缩[Raedt等人,2008]选择了一个程序的子集,最小化对示例性能的影响。相比之下,我们只考虑程序■■★,而不是示例。ALPS[Dumanˇci´c等人,2019]压缩事实,而我们压缩逻辑程序。KNORF[Dumanˇci´c等人,2021]通过将问题表述为COP来重构逻辑程序★◆■◆。与KNORF执行一阶重构不同,我们执行高阶重构★■■★。几种方法[Ellis等人,2018; Bowers等人★◆★,2023■◆; Cao等人,2023]通过搜索增加成本函数的局部变化(新的λ表达式)来重构函数程序。我们的区别在于我们
这些近期方法的主要限制是它们需要人类提供必要的抽象作为输入,即这些方法无法发现抽象。
当我们重构一个程序时,我们希望保持其语义。然而,我们只需要保持与头部谓词符号相关的语义。因此,我们考虑限制在一组谓词符号上的最小Herbrand模型■★★:
为了回答Q4◆★,我们比较了在不同领域中有无使用STEVIE发现的抽象的HOPPER的性能。
为了测试我们的论断,即在一个领域中发现的抽象可以在不同领域中重用,我们的实验旨在回答以下问题:

为了激发发现高阶抽象的动力◆■◆,考虑从示例中学习一个逻辑程序,以将输入字符串转换为大写,例如 [l■★,o,g,i■◆◆,c] 转换为 [L,O,G,I■◆★,C]。对于这个问题◆★■◆★■,我们可以学习以下程序:
本文的三个主要创新点是:(i)发现高阶抽象以重构逻辑程序的想法,(ii)将这个重构问题编码为 COP,以及(iii)展示发现的抽象在不同领域之间的转移■◆■。影响是我们能够大幅提高 ILP 系统的性能,与不发现抽象相比。此外,由于这个想法连接了 AI 的许多领域★★★,包括机器学习、程序合成和约束优化★■■◆★,我们希望这个想法能够吸引广泛的受众◆◆◆。
 中国科大在最优子集选取的问题研究中取得重要进展
第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序
中国科大在最优子集选取的问题研究中取得重要进展
第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序

 基于特征优化和支持向量机的航空发动机气路故障诊断
基于特征优化和支持向量机的航空发动机气路故障诊断