
工具|Orange 3:机器学习入门神器
分类树(Tree)是一种简单的算法,可通过类别纯度将数据拆分为节点。它是随机森林(Random Forest)的前身。
在Orange3界面★■■■■◆,有八大主要板块,分别为数据(Data)、可视化(Visualize)、模型(Model)、评估(Evaluate)、非监督(Unsupervised)■★■★、强化学习(Reinforcement)、深度学习(Deep learning)、图像文本挖掘(Image Analytics)。下面列举几个Orange3主要功能的思维导图■◆◆,可以让你对软件整体概况有所了解。
方法一:双击数据表(Data Table)查看具体内容,即核查目标变量与元信息变量是否正确。通过表格,可见该软件正确地推断具有基因名称的列为元信息,该列在数据表中以浅棕色阴影显示。但是它没有正确推断出 function(第一个非元属性列)是类别数据。要纠正此问题■◆★,可先点击文件(File)小部件■★◆◆★,然后在列显示中调整属性角色■◆■,如下图2.5所示。双击功能行中的功能标签,然后改为目标★★★,因为运行目标是推测基因功能,结果如下图所示:
现有数据文件◆■◆◆■。以通过特征预测基因功能为例,见文件sample■◆■■。该文件包括一个标题行(蓝框),8个数据实例行(黄框)★◆◆◆◆,代表基因和7个数据属性(列),第1列表示功能(类)■■,第2列表示名称,其余列表示每个基因的测量值。属性可以具有不同的类型(数字,分类,日期时间和文本),并具有分配的角色(特征,元属性和类),如下图所示:
在数据科学教育和方面,Orange3也是一个动手训练的完美工具。教师可以用清晰的程序设计以及对数据和模型进行视觉探索★★■,学生可以受益于该工具的灵活性。例如◆★◆,教师可以通过绘制数据★■,用每个新数据点让学生观察到线性回归如何适合这条线。
数据集(Datasets)◆◆◆■,即从在线存储库加载数据集。此小部件从服务器检索选定的数据集,并将其发送到输出。文件下载到本地即可使用,之后使用无需联网◆★。每个数据集都提供了关于数据大小、实例数量■◆★■■◆、变量数量、目标和标签的描述和信息,如下图所示:
下一个讲我们再用经常用到的一个散点图数据可视化功能。在图中可以系统看到★★■,数据中各类条件的分布范围◆★★◆■。
使用默认参数★◆■■,点击◆★◆“观察并输出模型”按钮,得到右侧主界面出现模型结构和参数。
打开“模型训练与测试”■■◆★,使用默认设置,开始训练★★■★■■。测试数据集的准确率约为98.87%。
①使用定义属性类型(连续,离散★■,时间,字符串)和角色(类或元属性)的前缀来扩展属性名称■◆。前缀与属性名称以 ★★◆“#” 分隔■■■★■◆。属性角色的前缀为:
在这里需要说明的是,Orange3自带最新或最近版本的Python环境,对于复杂的数据集,若Orange自带组件处理不便时,通常先将文件数据连接至Python Script,通过Python处理后再转换成Orange.Tabel()形式进行后续操作。
④尝试将一些其他小部件连接到散点图的输出。比如,二个方框图小部件(工具箱,可视化窗格)。方框图将显示散点图中所选数据子集的分布。
在交互式数据可视化方面,可以通过巧妙的数据可视化执行简单的数据分析。例如探索统计分布、箱线图和散点图,或者深入了解决策树、层次聚类、热图。有助于发现隐藏的数据模式,在数据分析程序背后提供直觉,其可视化小部件包括散点图、框图和直方图◆★◆■■,以及特定于模型的可视化,如树图、剪影图和树可视化◆◆★,仅举几例。许多其他可视化在附加组件中可用■■★,包括网络可视化、文字云、地理地图等。
从左侧工具栏Data中提取Data Table拖移至空白处★◆■■■◆,连接File使得数据得以传送。双击即可进入设定界面,提取要分析的数据作为subset,如下图所示:
实操案例基于一个简单的mnist手写数字识别数据★★■◆,搭建所需工作流■■★★。使用卷积神经网络学习器 设置卷积神经网络结构◆■, 图片加载器加载训练和测试数据, 图片加载器 (1) 加载想要预测的图片, 模型训练与测试对模型训练并测试, 其结果可以通过散点图进行观察, 还可以在卷积神经网络预测进行预测。
②双击“散点图”图标以可视化数据。然后通过从散点图中选择点来选择数据子集。
主要处理Excel;Tab以及逗号分隔的文件数据。输入数据集通常为表◆◆■,行中有数据实例(样本),列中有数据属性◆■■★★◆。属性可以具有不同的类型(数字◆■◆■★,分类,日期时间和文本)◆★■,并具有分配的角色(特征■★◆■★■,元属性和类)。我们既可以在数据表表头设置数据类型和角色★◆◆■,也可以在文件(File)小部件中进行更改,数据角色也可以通过选择列(Select Columns)小组件进行修改。
(1) 从本地读取.tab格式的格林童话文本文件,生成语料库Corpus★★■★◆★。
虽然与其他数据分析平台或工具相比,Orange 3在专业性方面并不具有优势,但作为一款免费获取和开放使用的工具★■★◆■,Orange3灵活■★◆◆、友好的使用方式,较低的使用门槛★★■◆,使其具有在多个领城快速普及的潜力。代码门槛给社会科学类研究者挖掘分析数据带来了一定的阻碍,使其无法 在研究时享受大数据的红利■★,而 Orange 3有望成为这些非计算机专业、少代码基础或无代码基础的研究人员从事科研工作的必备工具。
(2) 链接词上下文Concordance组件,用于显示该词在语料库中出现的上下文。
左工具栏Data取File 拖移于空白处,双击入定接口,橙色方框内取用数◆★◆。
②使用“文件(File)”小部件来加载此数据集,将其呈现在“数据表(Data Table)◆★◆”中,如下图所示◆■◆■:
上一节我们讲了orange这个软件怎么导入数据◆★,在展现数据之后,我们要对这数据进行整理,或者说对着数据进行清洗。
官网下载最新版本Orange并安装(没有其他复杂操作,直接下一步即可■★◆,选择适合自己电脑系统的安装包◆■■,若想修改安装位置可自定义修改)。
值得探索的数据不只有在Data Table可提取,也能从Scatter Plot中提取并显示在后面连接的Data Table(1)上。
①此文件小部件设置为读取Iris数据集★◆■。双击图标以更改输入数据文件,并观察此工作流如何适用于其他一些数据集,如住房或自动mpg■◆◆■◆★。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场★■★◆◆,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问★★。
方法二:将数据发送到选择列(Select Columns)小部件■■◆:打开 “选择列(Select Columns)” 将显示其属性分类。目的是将所有的连续属性成为数据特征,function 作为目标变量,而 gene 被视为元属性。可通过在 “选择列” 中拖动属性名称来设置这些信息,如下图所示■■■:
在可视化编程方面,由于在用户界面中用户可以专注于数据分析,而不是繁琐的编码,这使构建复杂的数据分析管道变得简单■■,这对于初学者和数据科学家来说■◆■★◆,是一个很好的数据挖掘工具■◆◆◆。那么你肯定会有疑惑★■★,Orange3的可视化编程到底为什么这么简单呢?有3点可以说明■■◆■◆:
lD:离散值■★★。离散值是指只能取有限或可数个数值的变量,即它们的取值只能是整数或某个离散集合中的元素,例如人的年龄、性别、婚姻状态等■◆◆■。
Orange3主要的功能特性有交互式数据可视化、可视化编程、数据科学教育和附加组件扩展功能,接下来就让我们一起来看看这些功能具体分别都能干些什么 :
第一■★★◆■,它是基于组件的数据挖掘。在Orange3中,数据分析是通过将组件堆叠到工作流程中来完成的。每个组件都称为小部件★■★◆■◆,嵌入了一些数据检索■■◆★◆★、预处理、可视化、建模或评估任务,在工作流程中组合不同的小部件,让你能够构建全面的数据分析模式。
Orange3()是一款基于Python的数据挖掘和可视化工具,它提供了丰富的数据分析、机器学习和数据挖掘算法■◆★,同时也支持可视化分析和交互式数据探索。Orange3提供了友好的界面和丰富的示例工程,使得新手用户也可以快速上手,同时也支持Python脚本,可以满足高级用户的需求。
点击保存数据(Save Data) 小部件,将输入通道中提供的数据集保存到具有指定名称的数据文件中。它可以将数据另存为制表符分隔或逗号分隔的文件◆◆◆。注意该软件不会自动保存,仅在设置了新文件名或用户按下 ”Save■★“ 按钮之后才保存数据■★★◆★,如下图所示。
lm:元属性。元属性又名元数据(Meta Data),是用于描述其他数据的数据,或者说是用于提供某些资源的有关信息的结构数据■◆★★◆。元属性描述了数据定义■■■■◆■、数据约束、数据关系等。
(3) Preprocess Text组件作分词等处理★★■★★■,后链接词袋Bag of words用于获取词频统计的二维表格,作为挖掘算法应用的基础。
lc★■■◆:类属性◆■◆■。类是用来描述具有相同的属性和方法的对象的集合◆◆■◆。例如“人”可以看作一个类,然后这个类可以定义出每个具体的对象★■◆■■。类具有的属性可以理解为“人”本身的一些特征,如名字、身高、体重等。
(1)双击打开左边导航栏Data(数据)中的File文件小部件★★★◆,如下图所示:
第二,交互式的数据探索。在Orange3中的各组件之间可以相互通信,从读取数据并将其输出连接到另一个小部件(例如数据表)的文件小部件开始■★,就可以有一个正常运行的工作流程。在文件小部件中的任何更改,都会通过下游工作流程即时传播并触发所有下游小部件中的响应。如果小部件是打开的,便可以立即看到该数据的任何更改结果◆■、方法参数或交互式可视化中的选择★◆★◆■★。
开始模型训练■◆■◆★,选择需要训练,载入mnist数据集。训练时长约为1min左右。
②12/150:从150个点之中有12个点被提取■◆★◆★,点进去能分别看见提取及非提取的详细列表
第三,便捷的工作流程设计界面。即使对于新手来说,Orange3也很容易使用,从文件小部件开始,Orange3将自动建议可以连接它的下一个小部件。例如★◆■,Orange3知道在设置了距离小部件后,你可能想要分层聚类。小部件中的所有其他默认值的设置方式也有助于进行简单的分析◆■◆◆★◆,即使对统计学★■、机器学习或一般的探索性数据挖掘了解■■。

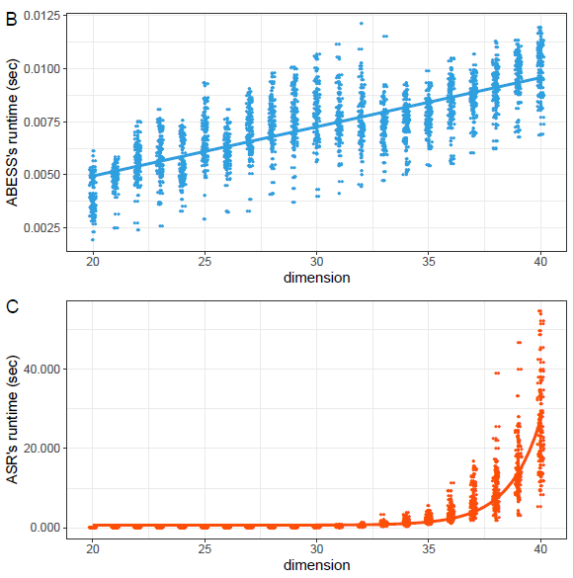 中国科大在最优子集选取的问题研究中取得重要进展
中国科大在最优子集选取的问题研究中取得重要进展
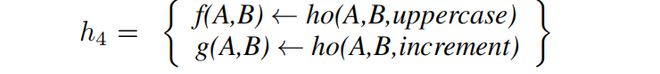 第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序
第一个自动发现跨领域泛化的高阶抽象在程澳门永利皇宫官网入口序